 |
Startseite Telefonbörse Telefondatenbank (Betatest) |
Telefon Forum |  |
 |
mehr als 8900 Themen und 56200 Antworten |
| Zurück zur Übersicht! Kategorie verlassen! |
Datenschutz | FAQ | Hilfe | Impressum | |||||
| Kategorie: > Sonstiges |
| TextCD bei Delegatic und Cityruf | |
| Münzersammler mathias77  gmx.net gmx.net(Mailadresse bestätigt) 19.12.2020 |
Hi, kann mir jemand was zum Datenübertragungsmodus TextCD sagen, mit dem man an Cityruf Texte senden konnte? Auch das Telefon Delegatic arbeitete damit, ebenso die MFV-Sender TipSend und TipSend 2. Es klingt, als würden zwei MFV-Töne je Textzeichen ineinander/ nacheinander wiedergegeben werden, um Zeichen zu Übertragen. Folgende Zeichen sind möglich: ABCDEFGHIJKLMNOPQRSTUVWXYZ ÄÖÜ Leerzeichen .,-?! 1234567890*# |

| |
| Anzahl der unterhalb stehenden Antworten: 16 |
| Münzersammler mathias77 gmx.net(Mailadresse bestätigt) 11.02.2021 |
Dieser Text bezieht sich auf den Beitrag von Steffen Froeschle kinobauer.ch vom 04.01.2021!  Das ist, um zum Telekom Delegatic und Siemens memoset kompatibel zu sein. Nur damit werden die Zeilen umgebrochen. |
|
| |
| Steffen Froeschle kinobauer.ch kinobauer kinobauer.ch(Mailadresse bestätigt) 04.01.2021 |
Dieser Text bezieht sich auf den Beitrag von Christoph Lauter vom 04.01.2021! Hallo Christoph, habe mir mal den TipSend2 vorgenommen und festgestellt, dass nach 20 Zeichen (Zeilenlänge Delegatic) ein automatischer Umbruch eingefügt wird, siehe Bilder:
|
||
|
| |||
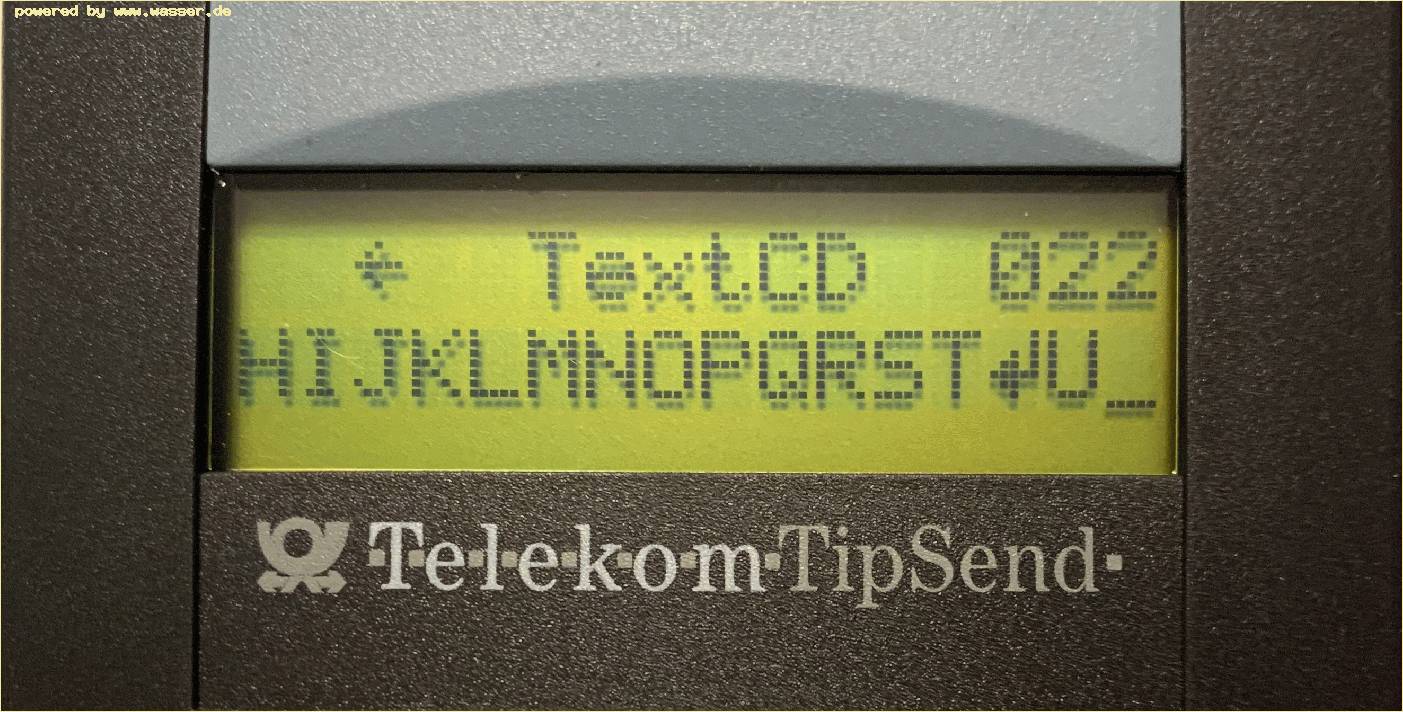
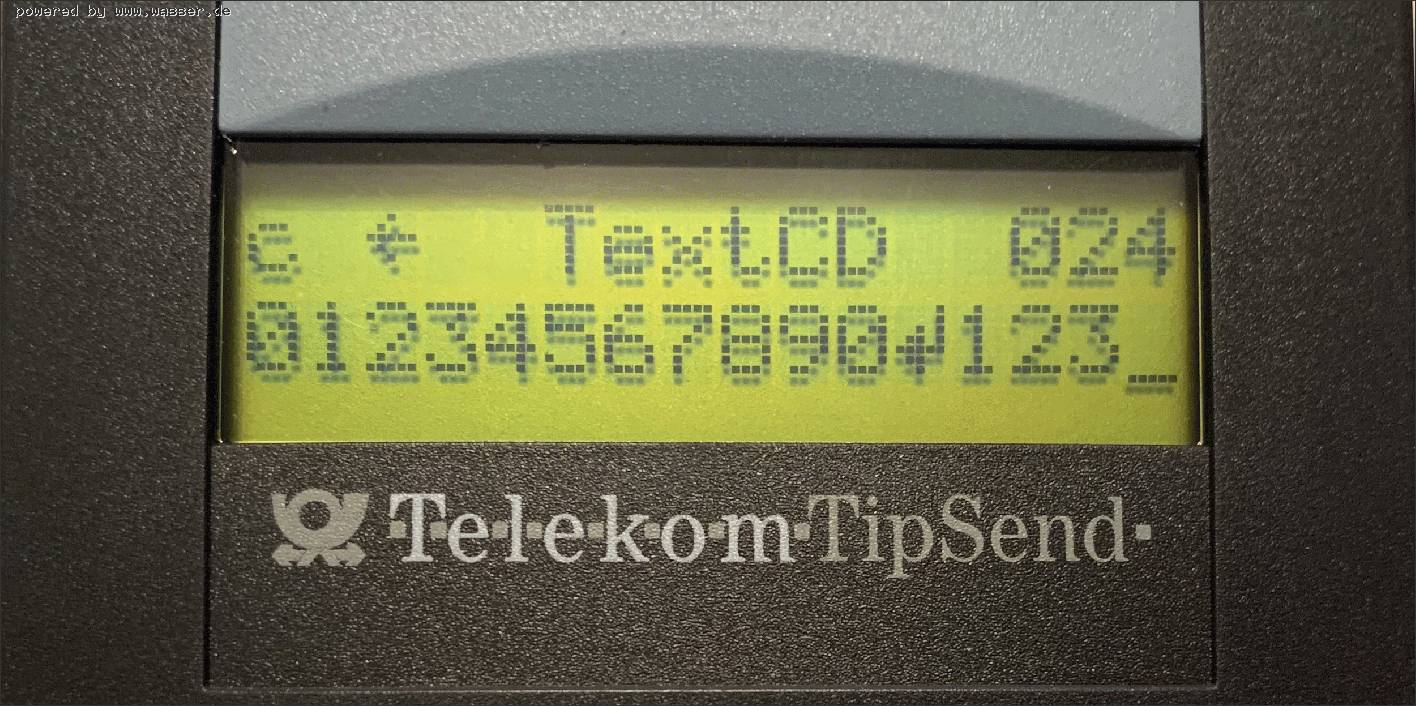
| Christoph Lauter (Mailadresse bestätigt) 04.01.2021 |
Dieser Text bezieht sich auf den Beitrag von Münzersammler vom 02.01.2021! Hallo, also nach unserem netten Gespräch heute (nochmals Danke), habe ich mich hingesetzt und ein Dekodierprogramm in Python geschrieben. Jeder Interessierte kann das Programm haben. Es ist ein Proof-of-Concept, funktionniert aber soweit ganz gut. Der Text, den du mir während unseres Gesprächs zugesendet hast, lautet: lauter@nudel:~/delegatic/program$ python delegatic.py ../raetsel.wav ??1HALLO CHRISTOPH!?96? Alle Nachrichten beginnen mit ??1 und enden mit 4 Zeichen ?XX?, wobei XX anscheinend eine Art Checksumme ist. Ich kann jetzt auch die von dir gesendete Datei mit allen Zeichen dekodieren. Es fällt auf, dass das Telefon/der Tipsend nach soundsovielen Zeichen einen Zeilenumbruch einfügt, den du so nicht gewollt hast: lauter@nudel:~/delegatic/program$ python delegatic.py ../TEXTCD_ALLE_ZEICHEN.WAV ??1ABCDEFGHIJKLMNOPQRST UVWXYZÄÖÜ .,-?!12345 6789*0# ?BE? Also, wie geht das ganze? Man muss 2 Dinge tun: man muss zunächst die Anwesenheit oder Abwesenheit von Frequenz-Impulsen finden. Man hat dann fallende und steigende Flanken (in der Hüllkurve sozusagen). Dann muss man nach einer steigenden Flanke ein DTMF-Zeichen suchen (0-9*#A-D). Man kann das DTMF Zeichen dann in einen Puffer schreiben. Dieses Zeichen ändert nach gewisser Zeit seine Spaltenfrequenz, behält aber seine Zeilenfrequenz bei. Sobald sich das Zeichen ändert (und zwar stabil ändert), muss man es speichern. Fällt nun die Flanke der Hüllkurve wieder, muss man das gespeicherte Zeichen ebenfalls in den Puffer kopieren. Am Ende der Nachricht hat man nun eine gerade Anzahl von DTMF-Zeichen, wobei in jedem Paar jedes der zwei Zeichen aus der gleichen Zeile auf einer DTMF-Tastatur stammt. Es gibt 64 solche Paare. Man kann jetzt jedes Paar in einen Buchstaben bzw. eine Ziffer oder ein Sonderzeichen übersetzen. Dabei decodiert sich 11 zu 1, 22 zu 2, 33 zu 3 usw. bis AA zu A und DD zu D. Man muss sich dann die DTMF-Tastatur mit vielen Spalten verlängert vorstellen. In der nächsten, ergänzten Spalte steht E, F, G, H, in der nächsten I, J, K, L usw. Der Sprung in der Spaltenfrequenz wählt nun die entsprechende dieser "virtuellen" Spalten aus. Die Sonderzeichen und Umlaute finden sich dann am Ende. In Python ist das mit einem Dictionary leicht realisiert. Mein Code ist wie gesagt auf Anfrage erhältlich. Er ist nicht sehr effizient und auch fehleranfällig. Ist die Aufnahmequalität zu schlecht (wie bei dem CityrufTextCD Prüftext zum Beispiel) scheitert die Dekodierung. Der Code basiert auf einem Algorithmus, der keine Online-Dekodierung zulässt. Das sollte sich, wenn nötig ändern lassen. Es stellt sich nun die nächste Frage: können wir SEG93 spielen? Und: wollen wir das Alles, zusammen mit Fotos, evtl. für die (englischsprachige) TCI-Zeitung aufschreiben? Bis dann! Christoph |
|
| |
| Christoph Lauter (Mailadresse bestätigt) 03.01.2021 |
Dieser Text bezieht sich auf den Beitrag von Münzersammler vom 02.01.2021! Hallo, Ich glaub' ich hab's verstanden. Ich werde das auch hier im Forum veröffentlichen, ich würde nur gerne noch mit Ihnen, Münzersammler, ein paar Details besprechen wollen bevor wir hier in die Öffentlichkeit gehen... Schon so soviel vorab: das ist (wahrscheinlich) ein 6-Bit Code, es müsste also 64 Zeichen geben. Ein paar sind anscheinend für Header etc. reserviert. Wenn man die Codierungsvorschrift sieht, heult man... Könnten wir evtl. einmal telefonieren? Ich bin unter der deutschen Nr. 09621/1659073 erreichbar (VoIP), lebe aber in Alaska, habe also 10 Stunden Zeitverschiebung. Wenn es hier 8 Uhr morgens ist, ist es in Deutschland 18 Uhr abends. Es wäre super, wenn Sie während unseres Gespräch bestimmte Zeichenfolgen schicken könnten. Vielen Dank! Christoph |
|
| |
| Münzersammler mathias77 gmx.net(Mailadresse bestätigt) 02.01.2021 |
Dieser Text bezieht sich auf den Beitrag von Münzersammler vom 02.01.2021! Der Umbruch fehlte. Dann habe ich auch die Prüftexte aufgenommen. Daher noch mal ein Archiv. https://www.xup.in/dl,74964447/TextCD_alle_Zeichen.zip/ |
|
| |
| Münzersammler mathias77 gmx.net(Mailadresse bestätigt) 02.01.2021 |
Dieser Text bezieht sich auf den Beitrag von Christoph Lauter vom 02.01.2021! Hallo Christoph, du meinst ungefähr so? https://www.xup.in/dl,81461091/TextCD_alle_Zeichen.zip/ Das sieht schon mal sehr interessant aus! Vielen Dank für Deine Mühe! |
|
| |
| Christoph Lauter (Mailadresse bestätigt) 02.01.2021 |
Dieser Text bezieht sich auf den Beitrag von Münzersammler vom 21.12.2020! Hallo, Danke. Ich habe das jetzt mal analysiert. Die 48 Zeichen werden als 56 Ton-Impulse codiert. Die Impulse haben die Frequenzen der DTMF-Töne, es werden aber bei manchen Impulsen 3 (sic!) DTMF-Töne verwendet (also nix Dual-Tone...) Hier meine Tabelle: 1: 700 1640 2: 700 1205 3: 700 1640 4: 770 1640 5: 850 1640 6: 945 1640 7: 700 1205 1340 8: 770 1205 1340 9: 850 1205 1340 10: 945 1205 1340 11: 700 1205 1480 12: 770 1205 1480 13: 850 1205 1480 14: 945 1205 1480 15: 700 1205 1640 16: 770 1205 1640 17: 850 1205 1640 18: 945 1205 1640 19: 700 1205 1340 20: 770 1205 1340 21: 850 1205 1340 22: 945 1205 1340 23: 770 1340 1640 24: 700 1340 1480 25: 770 1340 1480 26: 850 1340 1480 27: 945 1340 1480 28: 700 1340 1640 29: 770 1340 1640 30: 850 1340 1640 31: 945 1340 1640 32: 700 1205 1480 33: 850 1205 1480 34: 945 1205 1480 35: 700 1340 1480 36: 770 1340 1480 37: 850 1340 1480 38: 945 1340 1480 39: 700 1205 40: 700 1340 41: 700 1480 42: 770 1205 43: 770 1340 44: 770 1340 1640 45: 770 1480 46: 850 1205 47: 850 1340 48: 850 1480 49: 945 1205 50: 945 1340 51: 945 1480 52: 770 1340 1640 53: 850 1480 1640 54: 770 1640 55: 700 1205 1340 56: 770 1480 1640 Ich habe die Frequenzen auf 5Hz genau gerundet. Die Impulse haben eine Länge von ungefähr 90ms, da sehe ich also in einem Spektrumplot nur auf ca. 1/0.09=11 Hz genau. Gewisse Impulse wiederholen sich. Es kann also sein, dass ich da noch etwas übersehen habe. Ich bin mir aber praktisch sicher, dass da nie eine 4. Frequenz dabei ist. Ich habe den Eindruck, dass die Zeichen 123456789*0# direkt als DTMF codiert sind. Evtl. sind da ABCD auch noch dabei. Das lässt also noch 36 (32?) andere Zeichen übrig, die als seltsames 3-Ton DTMF codiert sein müssen. Für 36 Zeichen werden etwas mehr als 5 Bit benötigt. Es wäre hilfreich, mal Nachrichten mit nur einem A etc. zu haben. So könnte man Header und Nachricht evtl. trennen. Christoph Lauter |
|
| |
| Münzersammler mathias77 gmx.net(Mailadresse bestätigt) 21.12.2020 |
Dieser Text bezieht sich auf den Beitrag von Christoph Lauter vom 21.12.2020! Hier nochmal ein Upload in wav. https://www.xup.in/dl,98288064/TextCD_alle_Zeichen.wav/ Die Zeichenfolge ist: ABCDEFGHIJKLMNOPQRSTUVWXYZÄÖÜLeerzeichen.,-?!1234567890*#Zeilenumbruch |
|
| |
| Christoph Lauter (Mailadresse bestätigt) 21.12.2020 |
Dieser Text bezieht sich auf den Beitrag von Münzersammler vom 19.12.2020! Hallo, MP3 ist nicht wirklich für Analysen geeignet, da es ja hörpysiologische Effekte zur Komprimierung verwendet. Ich habe mir das mal angehört, das klingt wie MF, wie es in R1 und R2 Signalisierung verwendet wurde. Das wurde in der Auslandssignalisierung und auch innerhalb der USA viel verwendet. Ich denke sogar, dass West-Deutschland mit Ost-Deutschland per R2 verbunden war. MF ist ein 2 aus 6 Code. Das sind 6*5/2 = 15 Codes. Das ist für den Zeichenvorrat noch zu wenig. Vielleicht ist es ja eine Variante, die auf MF aufbaut. Der Unterschied von DTMF und MF ist, dass die MF Frequenzen "glatt" sind, also 700Hz, 900Hz etc. Das macht die digitale Erzeugung viel einfacher. Nur als Anmerkung: das sowjetische AON/CallerID System verwendet auch die MF-Töne. Christoph |
|
| |
| Münzersammler mathias77 gmx.net(Mailadresse bestätigt) 20.12.2020 |
Dieser Text bezieht sich auf den Beitrag von Detlef Genthe vom 20.12.2020! Schade, vielen Dank! Vielleicht hat ja noch jemand eine Idee. |
|
| |
| Detlef Genthe post telegenthe.de(Mailadresse bestätigt) 20.12.2020 |
Dieser Text bezieht sich auf den Beitrag von Münzersammler vom 20.12.2020! so nach Gehör würde ich sagen nicht, da sind ein paar zu hohe Töne dabei. Aber ich habe keine Möglichkeit das zu analysieren. |
|
| |
| Münzersammler mathias77 gmx.net(Mailadresse bestätigt) 20.12.2020 |
Dieser Text bezieht sich auf den Beitrag von Detlef Genthe vom 20.12.2020! Meine Telefon-Meßgeräte bekommen das auch alle nicht hin. Weder mein Hera Commutest II, noch mein Quante MLTT oder gar mein Bosse WPG 100, vom Bosse COP 3 brauche nicht gar nicht erst anzufangen... :( Denkt Ihr denn auch, daß das im Grunde MFV ist? |
|
| |
| Detlef Genthe post telegenthe.de(Mailadresse bestätigt) 20.12.2020 |
Dieser Text bezieht sich auf den Beitrag von Münzersammler vom 19.12.2020! so ganz primitiv, Handy mit DTMF-Empfänger-App an die PC-Lautsprecher gehalten, kommt nichts vernünftiges raus. 3-4 zufällig während der ganzen Sequenz erkannte Zeichen, immer andere. |
|
| |
| Münzersammler mathias77 gmx.net(Mailadresse bestätigt) 19.12.2020 |
@Detlef: Ja, ich habe so einen Sender. @Christoph: Nein, das ist der Falsche Modus Ich habe hier mal ein Beispiel aller möglichen Zeichen hochgeladen. Die Reihenfolge entspricht NICHT meiner vorherigen Liste. https://www.xup.in/dl,96191801/alle_Zeichen.mp3/ |
|
| |
| Christoph Lauter (Mailadresse bestätigt) 19.12.2020 |
Hallo, ich habe mal versucht, das in Asterisk nachzubauen. Die Codierung ist nicht wirklich kompliziert und in Recommendation T/CS 34-15 https://www.etsi.org/deliver/cept/34/3415CS.PDF dokumentiert. Im großen und ganzen werden nur die DTMF Codes 0-9 und * und # verwendet, nicht aber A-D. Eine Ziffer steht für einen Buchstaben, ein Präfix aus * und # wählt eine Spalte von Buchstaben aus. Der Code erfüllt die Fano-Bedingung und ist also leicht zu dekodieren. Christoph |
|
| |
| Detlef Genthe post telegenthe.de(Mailadresse bestätigt) 19.12.2020 |
hast Du so einen Sender? Es gibt für Smartphones DTMF-Empfänger-Apps. Damit könnte man, wenn es wirklich DTMF-Töne sind, ganz gut raus bekommen, was die Dinger senden. zwei MFV-Töne ergeben ja genau 8 Bit, genug für ASCII mit Parität. |
|
| |
| Werbung (2/-2) | |